The Lebesgue Integral
Building the integral that handles limits — from simple function construction through the convergence theorems that make measure theory the engine of modern probability and machine learning.
Abstract. The Lebesgue integral is the completion of a promise. Topic 25 built the framework — sigma-algebras, measures, measurable functions, simple functions — but stopped short of the payoff: an integral powerful enough to handle limits. The Riemann integral fails when you need to interchange a limit and an integral, which is exactly what probability theory and machine learning do constantly. The Lebesgue integral fixes this. We construct it in three stages: first, for simple functions (finite sums weighted by measures); second, for non-negative measurable functions (supremum over simple approximations from below); and third, for general measurable functions (splitting into positive and negative parts). The three convergence theorems — Monotone Convergence, Fatou's Lemma, and Dominated Convergence — are the reason this integral exists. Dominated Convergence, in particular, is the mathematical justification for every 'swap the gradient and expectation' move in stochastic optimization. Fubini's theorem extends the integral to product spaces, making iterated integration rigorous. Expected value, KL divergence, and the ELBO are all Lebesgue integrals — this topic makes that precise.
1. Three Puzzles the Lebesgue Integral Solves
Topic 25 built the measure-theoretic framework — sigma-algebras, measures, measurable functions, simple functions, null sets, “almost everywhere” — but stopped short of the actual payoff: an integral. We had the vocabulary in place to talk about integration in a measure-theoretic way, but no integral defined yet. This topic builds it.
The motivation is the same one that drove the original development of the theory in the early twentieth century. The Riemann integral, beautiful as it is, fails on three different kinds of question that we routinely need to answer in probability theory and machine learning. Each failure points at a property we need the new integral to have.
If the proofs in this topic feel more technically demanding than Topic 25, that’s accurate — we are now working with suprema of integrals and interchanges of limits, which is where measure theory earns its keep. The conceptual mode is the same (sets, measures, measurable functions), but the manipulations are harder. Expect to slow down at the convergence-theorem proofs.
Puzzle 1: The limit–integral interchange failure
Define a sequence of functions by
Each is a simple function: it equals on the interval and elsewhere. The Riemann integral is well-defined for every and equals
So the integrals are constant: for every .
Now look at the pointwise limit. For any fixed , eventually — specifically, for — and so for all sufficiently large . At , for every , so — a single point we can ignore. Putting these together,
So the pointwise limit equals almost everywhere, and any reasonable theory of integration should give .
But .
The Riemann integral provides no theorem that tells us when we are allowed to swap a limit and an integral. We are simply forbidden from doing it without justification, and there is no general justification available.
📝 Example 1 (The limit–integral interchange failure)
The sequence on has pointwise limit (for every ), but
This is the simplest possible witness that “limit of integrals” and “integral of limit” can disagree. The mass of — concentrated on a thin spike near — does not vanish in the limit, even though the spike itself does.
The Lebesgue integral comes with a precise theorem — the Dominated Convergence Theorem — that tells us exactly when the swap is legal: if for some integrable function , the swap is valid. The sequence above escapes every dominating function (any would have to satisfy on for every , forcing to be unbounded near in a non-integrable way), so its failure is not a defect of the theory but a genuine warning. By the end of Section 7 we’ll see this tightness from both sides: scenarios where DCT applies and the swap is valid, and the spike sequence above as a textbook example of what happens when the domination hypothesis fails.
Puzzle 2: The mixture distribution
Suppose a random variable has the following law: with probability it equals exactly (a point mass), and with probability it is drawn from the exponential density on . Computing the expected value requires integrating against a measure that is neither purely absolutely continuous nor purely discrete.
Try to write this expectation as a Riemann integral. The continuous part contributes which is a perfectly fine improper Riemann integral and evaluates to . But the point mass at contributes to the expectation, and there is no way to capture that ” with probability ” inside a Riemann integral framework — the value of any Riemann integral over a single point is always zero, regardless of how much probability is concentrated there.
In the Lebesgue framework, the entire expectation is one integral against a single mixed measure :
The point is not the numerical answer (which is the same either way — we got lucky here because contributes zero). The point is that the framework handles continuous and discrete components uniformly, with no special-case grafting. Mixtures of densities and atoms are everywhere in real-world ML — quantized neural networks, censored data, discrete-continuous outcome models — and the Lebesgue integral is what makes them legal mathematics rather than ad-hoc bookkeeping.
Puzzle 3: The gradient–expectation swap in SGD
When you train a model with stochastic gradient descent, the move at the heart of the algorithm is
The left side is “differentiate the population loss”; the right side is “average the per-sample gradients.” We use this identity every time we compute a minibatch gradient and call it an unbiased estimator of the population gradient.
Look closely at what is being claimed. The gradient is a limit (it’s the limit of difference quotients in ). The expectation is an integral. So the identity is
This is exactly a “limit of integrals equals integral of limit” claim. Without a convergence theorem, swapping the limit and the integral is just wishful thinking. The Dominated Convergence Theorem provides the conditions under which the swap is legal: if there exists an integrable such that for all in a neighborhood, the interchange is valid.
In practice, ML papers cite this without naming it. Bounded gradients (gradient clipping), Lipschitz losses, and bounded-support data distributions are all ways to manufacture an integrable dominator. Every single SGD convergence proof in the literature implicitly invokes DCT at this step. Forward link: Gradient Descent.
Three failures, three needs: a convergence theorem for limits and integrals, a unified treatment of mixed measures, and a justification for swapping derivatives with expectations. The Lebesgue integral delivers on all three, and the rest of this topic shows how.
2. The Integral for Simple Functions
We start at the foundation. Recall from Topic 25 that a simple function on a measure space is a function of the form where are real numbers, are measurable sets, and the partition (or at least cover) the relevant part of . A simple function takes only finitely many distinct values, each on a measurable set.
We already know what simple functions are. Now we give them an integral. The definition is the only reasonable one: if takes value on the measurable set , then the integral of should be — the “height times width” principle, with “width” measured by instead of by interval length.
📐 Definition 1 (Lebesgue integral of a non-negative simple function)
Let be a measure space and let be a non-negative simple function (, , the disjoint). The Lebesgue integral of with respect to is with the convention (so a coefficient of zero on an infinite-measure set contributes zero, not “indeterminate”).
The convention is essential. Without it, we couldn’t integrate the zero function over an infinite-measure space. With it, for every measure , which is exactly what we want.
📝 Example 2 (The Dirichlet function has Lebesgue integral 0)
Take (Lebesgue measure on ) and . This is a simple function: it takes value on and value on the rest of . From Topic 25, every countable set has Lebesgue measure zero, so . The integral is This is the answer the Riemann integral could not give us. Topic 25’s opening puzzle is now closed: the Dirichlet function is Lebesgue-integrable, and its integral is exactly the value our intuition demanded.
📝 Example 3 (Integration against a Dirac measure evaluates at the point)
Let be the Dirac measure at : if and otherwise. For any simple function , where is the unique with . In other words, integrating against just evaluates the function at : . This generalizes to all measurable functions in the next section, and it is the precise mathematical sense in which a “point mass” picks out a single value.
The integral of simple functions has exactly the algebraic structure we want — it is linear in the function and monotonic with respect to pointwise inequalities. The proof is a straightforward but careful unwinding of the definition.
🔷 Theorem 1 (Linearity and monotonicity for simple functions)
Let be non-negative simple functions on and . Then is a non-negative simple function and Moreover, if pointwise (or even just -a.e.), then
Proof.
We prove linearity first; monotonicity follows from it.
Step 1: A common refinement. Suppose and , where the partition the support of and the partition the support of . Form the joint refinement consisting of the sets . These are measurable (intersections of measurable sets), pairwise disjoint, and they cover the union of supports. On each , takes the constant value and takes the constant value , so takes the constant value . We have rewritten everything on a single common partition.
Step 2: Compute on the refinement. With everything on the refinement, the integrals are sums:
The first and second sums recover the original definitions of and because by additivity of on the disjoint , and similarly for . The third sum splits as
That is linearity.
Step 3: Monotonicity. Suppose pointwise. On the common refinement, this means for every with . (If the term contributes nothing.) Summing over :
If only -almost everywhere — that is, the set has measure zero — then on the common refinement the offending values have and contribute zero to both sums. The same chain of inequalities goes through.
💡 Remark 1 (Well-definedness of the simple-function integral)
The definition depends on the representation that we chose. A given simple function has many such representations — we could refine the further, or we could merge sets that share the same coefficient. The proof above shows that the value is independent of representation: any two representations have a common refinement, and the integral computed on the common refinement matches the integral computed on either original. So is a well-defined number, not a function-of-presentation.
3. The Integral for Non-Negative Measurable Functions
Now we extend the integral from simple functions to arbitrary non-negative measurable functions. The strategy is one of the central constructions in real analysis: define the integral as the supremum of the integrals of all simple functions that lie underneath. This works because (a) every non-negative measurable function is the pointwise limit of an increasing sequence of simple functions (Topic 25, Theorem 5), and (b) the integral on simple functions is monotone, so taking the sup of integrals of approximations from below is a sensible analogue of the Riemann integral’s “lower sum.”
📐 Definition 2 (Lebesgue integral of a non-negative measurable function)
Let be a non-negative measurable function on . The Lebesgue integral of with respect to is The supremum is taken over all non-negative simple functions that lie pointwise below .
A few features of this definition deserve immediate attention.
💡 Remark 2 (The integral can be infinite — and that is the point)
The supremum on the right side may be . We allow this. A non-negative measurable function for which is integrable in the extended sense but not Lebesgue-integrable in the strict sense. Reserving as a valid value of the integral lets us state the convergence theorems below without piling on extra hypotheses every time. A function with is called integrable (or, more carefully, summable), and we write once we have extended the definition to general — not just non-negative — measurable functions in Section 4.
📝 Example 4 (Recovering the improper integral $\int_0^\infty e^{-x} \, dx = 1$)
Let on and . We can build a simple-function approximation from below as follows. For each , partition into subintervals of equal length , set equal to the infimum of on each subinterval, and set outside . Each is a non-negative simple function with , and a direct computation shows as . By the definition, . The reverse inequality follows from pointwise and a similar refinement argument (or — more cleanly — from the comparison-with-Riemann theorem in Section 8). The conclusion is , exactly the value the improper Riemann integral gives.
📝 Example 5 (The Cantor set has Lebesgue measure zero — and so does its indicator)
Let be the standard middle-thirds Cantor set from Topic 25, and consider . From Topic 25, . The function is itself a simple function (one set, coefficient 1), so the simple-function integral applies directly: The Cantor set is uncountable — so is non-zero at uncountably many points — but the Lebesgue integral correctly assigns it value zero. “Uncountable” and “has positive measure” are unrelated concepts; the Cantor set is the canonical example of a set that is simultaneously uncountable and Lebesgue-null.
The integral on non-negative measurable functions has one immediate application that is worth proving right now, because it is the source of every tail bound in probability and ML.
🔷 Proposition 1 (Markov's inequality)
Let be measurable and let . Then
Proof.
Let . The set is measurable because is measurable. Consider the simple function . By construction on , and off , so pointwise. The integral of is
By the definition of as a supremum over simple functions ,
Dividing both sides by (which is positive):
💡 Remark 3 (Markov's inequality is the foundation of every tail bound in probability)
Markov’s inequality looks innocent — three lines of proof, no clever tricks — but it is the seed crystal for the entire theory of concentration of measure. Specializing gives Chebyshev’s inequality (set ), Hoeffding’s inequality (set for some and tune), and ultimately the Chernoff–Cramér bound that powers VC dimension and Rademacher complexity arguments. The elementary version for finite/countable sample spaces, together with Chebyshev and the full Hoeffding derivation, was developed in Probability & The Union Bound; the present statement is its Lebesgue-integral generalization. Every “with high probability” statement in modern statistical learning theory rests on a Markov-style tail bound applied to a cleverly chosen non-negative random variable. Forward link: Concentration Inequalities.
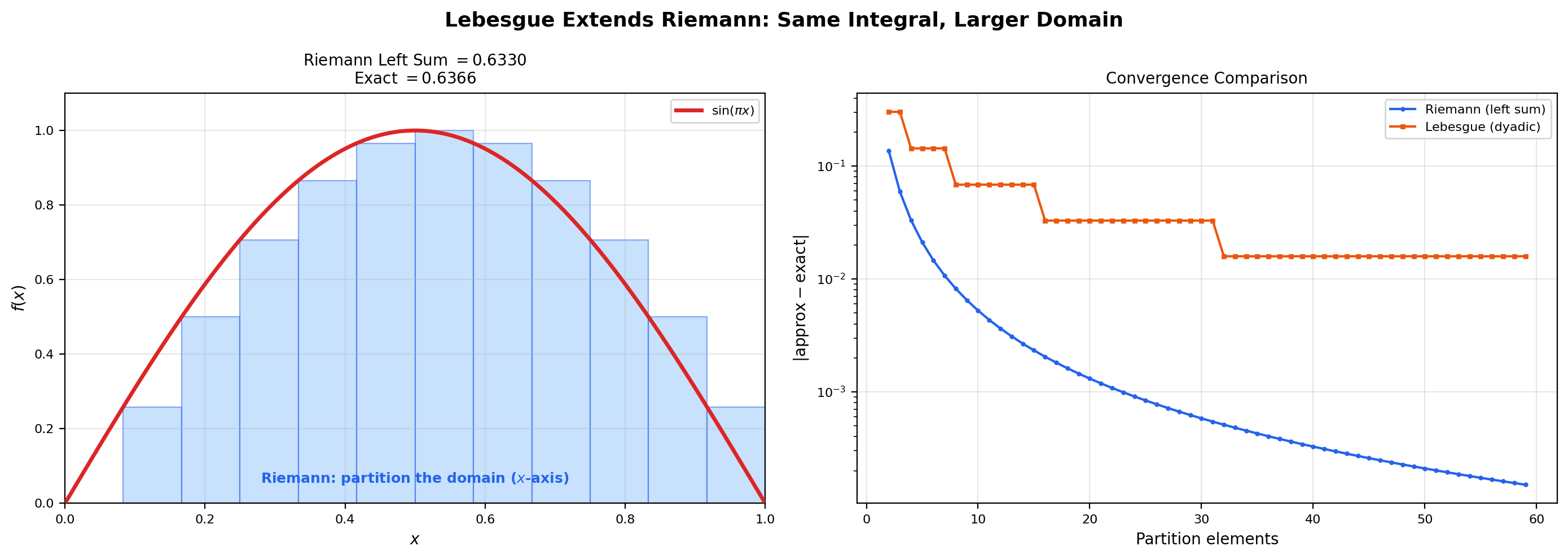
The interactive viz below makes the supremum construction concrete. As you increase the dyadic refinement level, the simple-function staircase climbs upward toward and the integral climbs upward toward . The supremum is the limit of this climbing process — it is what the construction computes in the limit, not a single staircase you can draw on the page.
The half-cycle of a sine wave on [0, 1]. Exact integral 2/π ≈ 0.6366. The simple function s_n is the largest dyadic staircase below f at this level — the supremum over all such staircases as n → ∞ is the Lebesgue integral ∫ f dλ.
4. The Integral for General Measurable Functions
So far we have only integrated non-negative functions. To integrate a general measurable function (positive or negative), we split it into its positive and negative parts and integrate each separately.
📐 Definition 3 (Positive and negative parts)
For any measurable function , define Both and are non-negative measurable functions. They satisfy
A small visual: keeps the positive parts of and zeros out the negative parts; does the opposite (and flips the sign so it is also non-negative). Their difference is , and their sum is . Both are non-negative, so the previous section applies to each.
📐 Definition 4 (Lebesgue integral of a general measurable function)
Let be a measurable function on . If at least one of and is finite, the Lebesgue integral of with respect to is If both are finite, is Lebesgue-integrable and we write . The space consists of all measurable functions with .
The reason we require at least one to be finite is to avoid the indeterminate form . If both and are infinite, the integral is left undefined. (In some treatments such functions are called “non-integrable” or “improperly integrable”; we will not need that distinction in this topic.)
📝 Example 6 ($\int_{-\pi}^{\pi} \sin(x) \, d\lambda = 0$ — positive and negative parts cancel)
The function on is non-negative on and non-positive on . Its positive part is and its negative part is . By symmetry, Both integrals are finite, so , and
The definition extends linearity from simple functions to all of , but the proof requires a small bit of bookkeeping.
🔷 Theorem 2 (Linearity of the Lebesgue integral on $L^1(\mu)$)
Let and . Then and
Proof.
The strategy is to reduce to the non-negative case, where linearity is already established (as a limit of the simple-function linearity from Theorem 1).
Step 1: Non-negative linearity. First we extend Theorem 1 from simple functions to general non-negative measurable functions. If are measurable and , choose increasing sequences of non-negative simple functions and (Topic 25, Theorem 5). Then is a non-negative simple function with . By the definition of the integral as a supremum and Theorem 1 applied at each step,
The sup of a sum of non-negative terms equals the sum of sups (each term is non-decreasing in ), so this becomes
We will give a tighter version of this “sup of sum” step inside the proof of the Monotone Convergence Theorem in Section 5; for now we treat it as the natural extension of Theorem 1 to limits.
Step 2: Subtraction by splitting. For general , write with both (their integrals are both finite, since ). Similarly . The sum has positive and negative parts that satisfy
This identity is the key. The two decompositions of — its own canonical split, and the sum-of-splits — are not the same simple-function decomposition (the second one is “wasteful” in that it can have and both non-zero at the same point, which the canonical decomposition would simplify), but they sum to the same thing. Rearranging:
Both sides are non-negative measurable functions, so we can apply Step 1 (non-negative linearity) to each. Integrating:
All six integrals are finite (everything is in ), so we can rearrange:
The left side is by Definition 4; the right side is . So .
Step 3: Scalar multiplication. For , and , so . For , and , so . Either way, scalar multiplication pulls through.
Combining additivity (Step 2) and scalar multiplication (Step 3), .
💡 Remark 4 (The Lebesgue integral strictly extends the Riemann integral)
If is bounded and Riemann-integrable, then is Lebesgue-integrable on (with respect to Lebesgue measure restricted to ) and the two integrals agree: We will prove this in Section 8 (Theorem 6). The converse is false: the Dirichlet function on is Lebesgue-integrable (Example 2) with integral , but it is not Riemann-integrable (Topic 25, Section 1). So the Lebesgue integral is a strict extension — the same functions as before plus genuinely more.
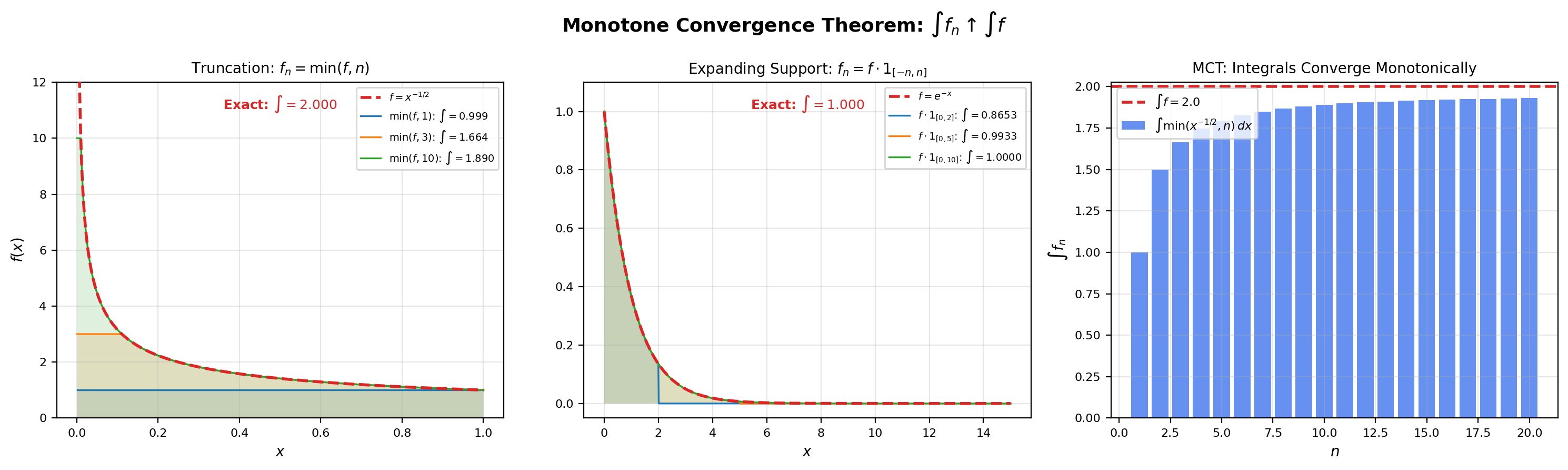
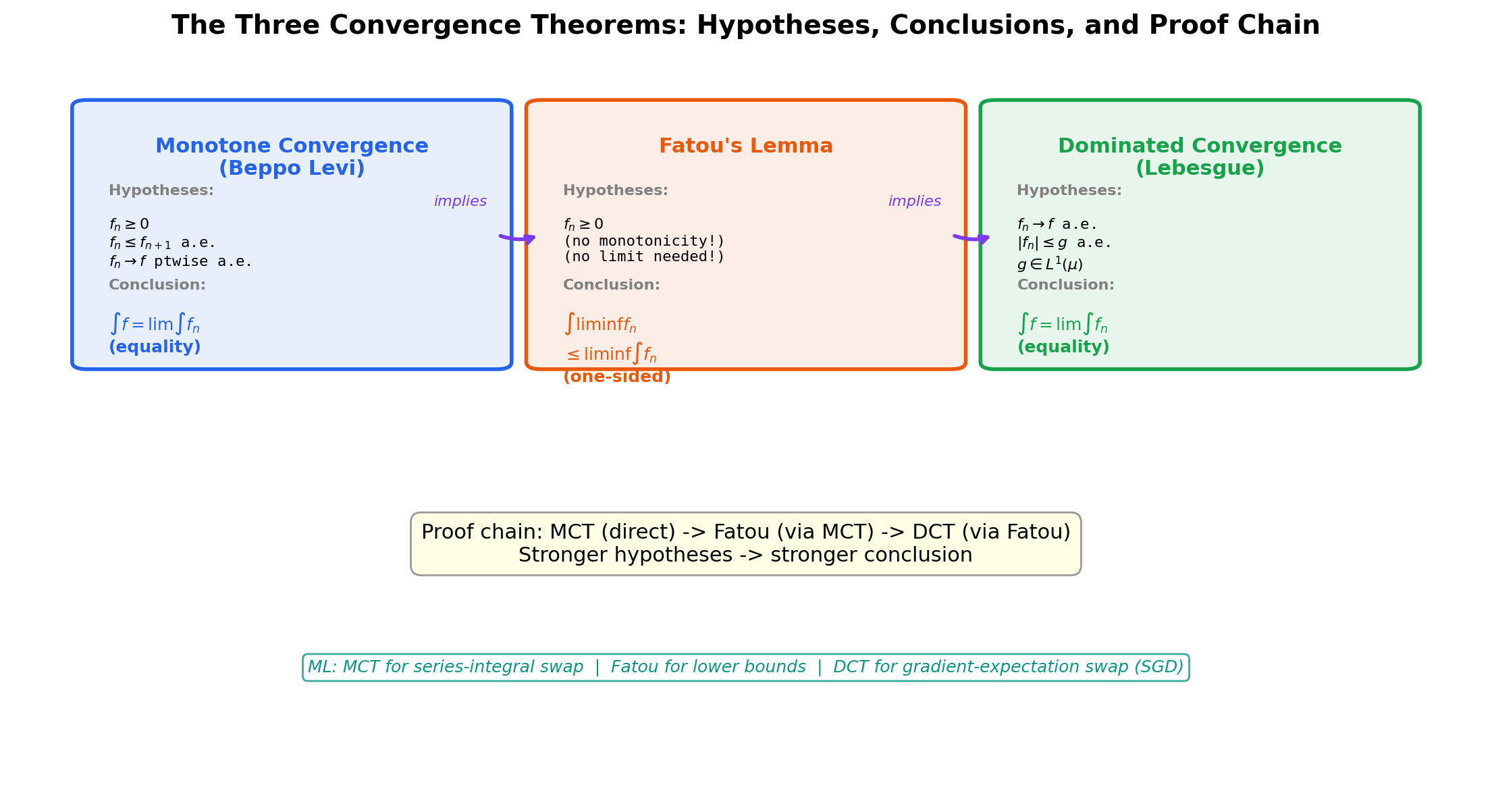
5. The Monotone Convergence Theorem
The first of the three convergence theorems. The Monotone Convergence Theorem — historically due to Beppo Levi (1906) — handles the easy case where is an increasing sequence. Increasing means we never lose mass, so the limit-integral interchange goes through with no extra hypotheses.
🔷 Theorem 3 (Monotone Convergence Theorem (Beppo Levi))
Let be a sequence of non-negative measurable functions on with and let be the pointwise limit (which exists in because the sequence is non-decreasing). Then is measurable and
The interactive viz below shows three monotone-convergence sequence types — truncation , expanding support , and the dyadic simple-function staircase — and the corresponding integral values climbing toward the limit. Try each and see how the bar chart of converges to from below.
Truncate f(x) = 1/√x at height n. As n → ∞ the cap rises and f_n ↑ f. The integrals climb from a small value toward 2 = ∫ f. MCT predicts: ∫ f_n ↑ ∫ f because f_n is non-decreasing and converges pointwise to f.
The proof is the most technically demanding piece of this topic and is worth working through carefully. It is also the prototype for every other “limit and integral commute” argument we’ll see.
Proof.
We must show . The plan is to prove and separately. The direction is trivial; the direction is where the work happens.
Step 1: .
Since for every , monotonicity of the integral gives for every . Taking the supremum (which equals the limit because the sequence is non-decreasing — a consequence of monotonicity applied to ),
Step 2: .
This is the harder direction. By Definition 2, is a supremum over simple functions with . So it is enough to show that for every such ,
Fix one such simple function with .
Step 2a: A scaled cutoff trick. Pick any . Define
The set is measurable (it is a level set of the difference , which is measurable). Crucially, the sets are increasing: implies that if then , so . And their union covers all of (well, all of except a null set): for any fixed , the sequence converges to (the strict inequality holds wherever because ; on the inequality holds trivially, so for every ). So up to a null set.
Step 2b: Bound from below using . Restrict the integral to :
(The first inequality is monotonicity: pointwise, since the indicator is at most and .) On we have by definition, so
(The second equality uses linearity from Theorem 1.) Combining the two displayed inequalities:
Step 2c: Send . The sets are increasing in for each , with union (up to a null set). By continuity of measure from below (Topic 25, Theorem 1, second form),
So as . Plugging this into the bound from Step 2b:
Step 2d: Send . The bound holds for every . Letting ,
Step 2e: Take the supremum over . This bound holds for every simple function with . Taking the supremum over all such on the right and using Definition 2,
This is the inequality we needed. Combined with Step 1, we get equality: .
The “scaled cutoff” trick — picking to give ourselves room, then sending at the end — is a recurring move in measure theory. It is the technical engine behind every “lower-semicontinuity” type argument.
📝 Example 7 (Series as integrals against counting measure)
Let be the counting measure on : is the cardinality of for finite , and otherwise. A function is just a sequence with , and the Lebesgue integral against is the sum .
Apply MCT to the partial-sum sequence . Each is a non-negative simple function with . The sequence is increasing pointwise (each adds one more non-negative term). The limit is , and . MCT says which is just the definition of an infinite series. MCT specializes to “the series of non-negative terms equals the limit of partial sums” — a fact we already knew, but now justified inside the unified Lebesgue framework.
A clean corollary of MCT is the swap of sum and integral for non-negative functions — a result we will use repeatedly.
🔷 Corollary 1 (Sum–integral swap for non-negative functions)
Let be a sequence of non-negative measurable functions on . Then
Proof: apply MCT to the partial sums . The sequence is non-negative and increasing, with pointwise limit . By Theorem 1 (linearity for finite sums of simple functions, then promoted to non-negative measurable functions in Theorem 2 Step 1), . MCT gives .
6. Fatou’s Lemma
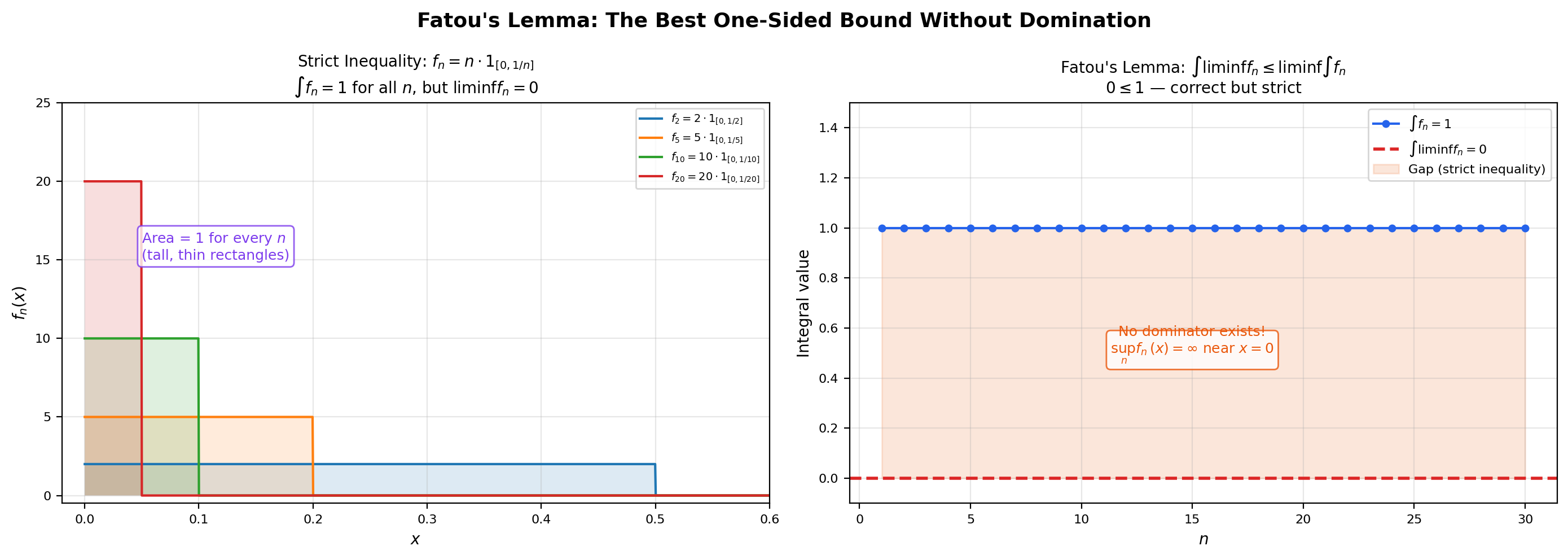
MCT requires the sequence to be increasing. What if it isn’t? Fatou’s Lemma gives the next-best thing: a one-sided inequality that holds for any sequence of non-negative measurable functions, with no monotonicity assumption.
🔷 Theorem 4 (Fatou's Lemma)
Let be a sequence of non-negative measurable functions on . Then
A reminder on the notation: for any sequence of extended reals, — the “eventual” lower bound on the sequence. For functions, is the pointwise at each point.
Proof.
Define a new sequence
The function is the pointwise infimum of the tail . By the standard argument (intersection of measurable level sets), each is measurable and non-negative.
Key observation 1: is increasing. As grows, the set shrinks, and the infimum over a smaller set is at least as large as the infimum over a larger set:
So .
Key observation 2: . Trivially: is the infimum of , which includes itself, so pointwise. By monotonicity,
Key observation 3: . By definition,
So converges pointwise to , and the convergence is monotone-increasing (Observation 1).
Apply MCT to . All three hypotheses of MCT hold: is non-negative, measurable, and monotone-increasing with pointwise limit . So
Combine with Observation 2. From Observation 2, , so the limit on the left is bounded by the of the right:
(Note: we use on the right rather than , because does not necessarily converge — it could oscillate. Whatever it does, from below, and stays below the of .) Combining with the previous display:
Fatou’s Lemma is a one-sided inequality, and the example below shows that the inequality can be strict — equality is not guaranteed.
📝 Example 8 (Strict inequality in Fatou: the spike sequence)
Take on — the same sequence from Example 1. Then pointwise for every , so everywhere (well, almost everywhere — the value at tends to , but a single point is null). Therefore But for every , so .
Fatou’s Lemma gives — correct, but strict. The mass of does not vanish in the integral even though it vanishes pointwise. This is the same phenomenon we observed in Puzzle 1 from Section 1: pointwise convergence does not always imply convergence of integrals.
💡 Remark 5 (Fatou cannot be promoted to equality without extra hypotheses)
The strict inequality in Example 8 shows that Fatou’s Lemma cannot in general be improved to equality. Some additional structure on the sequence is required to recover equality. Monotone Convergence gives one such structure (an increasing sequence), and Dominated Convergence in the next section gives another (existence of an integrable dominator). Without one of these extra assumptions, Fatou’s one-sided inequality is the best we can say.
7. The Dominated Convergence Theorem
The crown jewel. The Dominated Convergence Theorem is the result that justifies the limit-integral interchange in nearly every modern application — including the gradient–expectation swap that drives stochastic gradient descent.
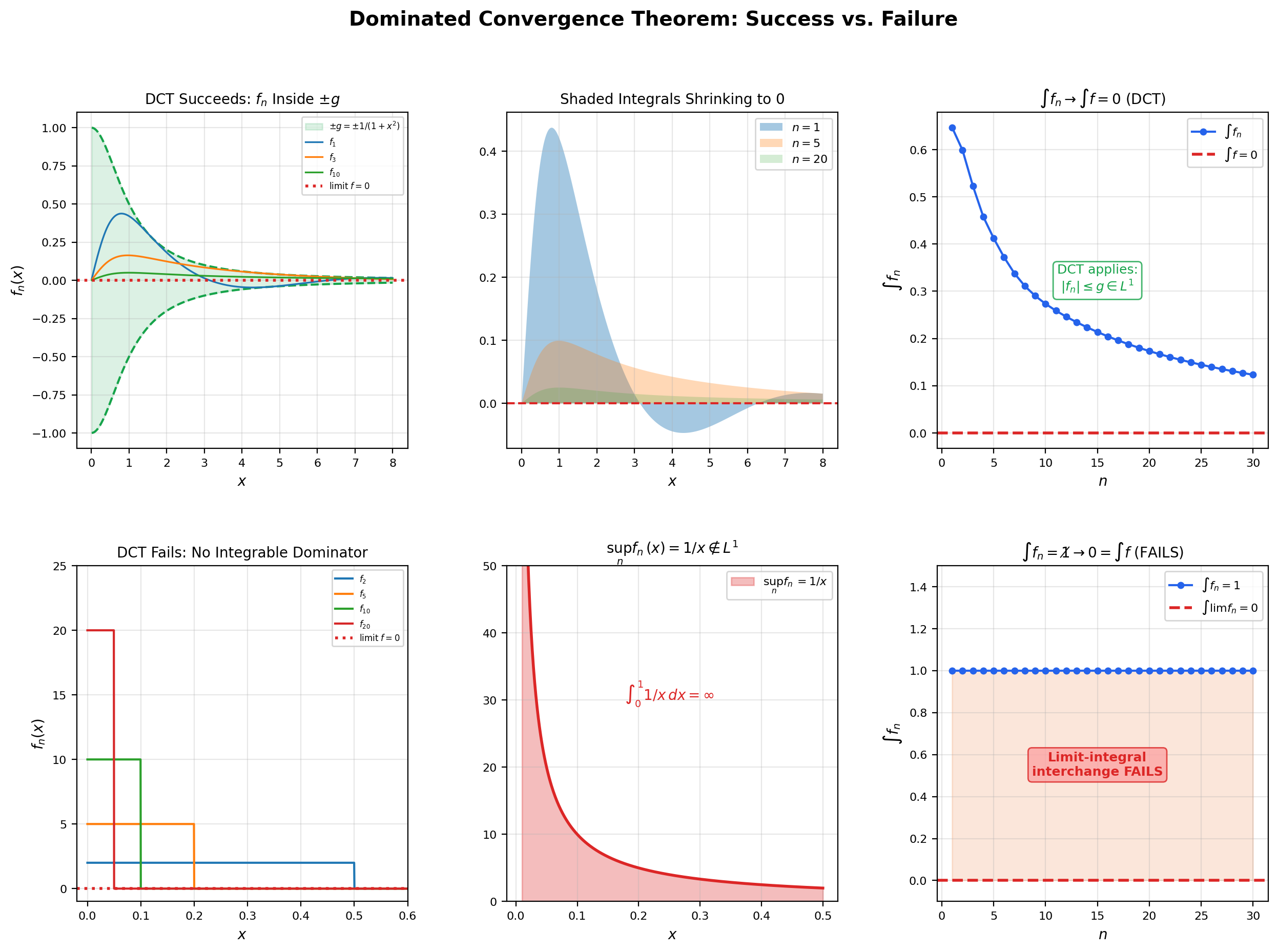
🔷 Theorem 5 (Dominated Convergence Theorem (Lebesgue))
Let be a sequence of measurable functions on with pointwise -a.e. Suppose there exists an integrable function (i.e., ) such that Then and Equivalently, — limits and integrals commute.
The flagship visualization for this topic is below. It contrasts two scenarios where DCT applies (sequences that have an integrable dominator and whose integrals do converge to the integral of the limit) with one scenario where DCT does not apply (the spike sequence from Example 1, which has no integrable dominator and whose integrals do not converge). Toggle between scenarios and watch the integral history bar chart on the right; the contrast is the conceptual heart of DCT.
f_n(x) = sin(x/n) / (1 + x²). As n → ∞ the argument x/n shrinks toward 0, so sin(x/n) → sin(0) = 0 and f_n → 0 pointwise (not by oscillation cancellation, but because the argument itself collapses). Dominator g(x) = 1 / (1 + x²) is integrable on [0, ∞) with ∫ g = π/2, and |sin(x/n)| ≤ 1 gives |f_n| ≤ g. DCT applies, and ∫ f_n → 0 = ∫ f. DCT predicts: ∫ f_n → ∫ f because |f_n| ≤ g and ∫ g < ∞.
The proof uses a slick double-application of Fatou’s Lemma — once to a pair of non-negative sequences manufactured from and the dominator .
Proof.
The strategy is to apply Fatou’s Lemma to two sequences: and . Both are non-negative because implies , so and .
Step 1: is integrable. Pointwise convergence and together imply . By monotonicity, so . The integral is therefore well-defined and finite.
Step 2: Apply Fatou to . The sequence is non-negative and converges pointwise to . Fatou’s Lemma gives
By linearity (Theorem 2),
(The constant pulls out of the .) Subtracting from both sides — legal because is finite — we get \int f \, d\mu \;\leq\; \liminf_{n \to \infty} \int f_n \, d\mu. \tag{$\star$}
Step 3: Apply Fatou to . The sequence is also non-negative and converges pointwise to . Fatou’s Lemma gives
Linearity again:
The key move on the right: , so . Subtract and multiply both sides by (which flips the inequality): \limsup_{n \to \infty} \int f_n \, d\mu \;\leq\; \int f \, d\mu. \tag{$\star\star$}
Step 4: Combine and . From and ,
Equality must hold throughout. In particular, , which means exists, and its common value is .
The proof is short once you see the trick: manufacture two non-negative sequences from and the dominator, apply Fatou to each, and let the upper and lower bounds collapse on . The hard work was in MCT (which underlies Fatou); DCT is a clean consequence.
📝 Example 9 (DCT applied: $\int_0^\infty \sin(x/n) / (x^2 + 1) \, dx \to 0$)
For each , define on . As , for every , so pointwise. (The convergence is even uniform on bounded intervals.)
We need a dominator. Note that for every and , so Set . Then , so is integrable. DCT applies, and This is the same sequence the flagship viz in this section uses. (Note: the related sequence with high-frequency oscillation also has , but for a different reason — the Riemann-Lebesgue lemma rather than DCT, since does not converge pointwise. Both reach the same conclusion via different theorems.)
📝 Example 10 (DCT justifies differentiation under the integral sign)
Let be a function with the following properties: for each fixed , ; for each fixed , is differentiable in ; and there is an integrable function with on some interval containing the point of interest. Then
The proof is exactly DCT applied to the difference quotient: as , the function converges pointwise to , and the mean value theorem bounds the difference quotient by , an integrable dominator. DCT gives the limit-integral swap.
In machine learning, is the per-sample loss as a function of parameters and data, and the integral is the population risk. The displayed identity is exactly the gradient–expectation swap, the move at the heart of every SGD convergence proof: .
💡 Remark 6 (The domination hypothesis is essential — do not skip it)
The spike sequence from Example 1 is the canonical witness that the domination hypothesis cannot be dropped. Any candidate dominator would have to satisfy on for every , so near , which is not integrable on . There is no integrable dominator. DCT therefore does not apply, and indeed the conclusion fails: for every , but . Whenever you write down an SGD-style identity that swaps a limit and an integral, the cost of skipping the domination check is exactly this kind of failure — silent and wrong, with no warning from the theorem.
8. Comparison with the Riemann Integral
Time to tie up Remark 4 from Section 4 with a real proof. Every Riemann-integrable function is Lebesgue-integrable, and the two integrals agree. The Lebesgue integral is therefore a strict extension of the Riemann integral — same answers on the old domain, plus new answers on a larger class of functions.
🔷 Theorem 6 (Riemann-integrable implies Lebesgue-integrable)
Let be a bounded function. If is Riemann-integrable on , then is Lebesgue-integrable on (with respect to Lebesgue measure restricted to ), and
Proof.
We give the proof in sketch form; the details are spelled out in Royden §4.3.
The Riemann integral exists and equals if and only if for every there is a partition of such that , where and are the upper and lower Darboux sums.
The upper and lower Darboux sums are themselves integrals of step functions. Specifically, where is the step function equal to on each subinterval, and where takes the supremum on each subinterval. Both and are simple functions on — their integrals exist by Definition 1 and equal the Darboux sums by direct computation.
Refining the partition (taking common refinements as shrinks) produces an increasing sequence of ‘s and a decreasing sequence of ‘s, with everywhere. By Riemann-integrability, . Taking the pointwise limits and (which exist almost everywhere by the increasing/decreasing structure), we get with . This forces almost everywhere, so agrees with a measurable function () almost everywhere, hence is itself measurable. Applying MCT to :
The Riemann and Lebesgue values agree.
The converse is much sharper — it tells us exactly which bounded functions are Riemann-integrable. The criterion is purely measure-theoretic: discontinuities only matter on a set of positive measure.
🔷 Theorem 7 (Lebesgue's criterion for Riemann integrability)
Let be a bounded function. Then is Riemann-integrable on if and only if the set of points at which is discontinuous has Lebesgue measure zero.
💡 Remark 7 (Lebesgue's criterion closes the Riemann question)
The “only if” direction is the powerful one: it says Riemann-integrability forces the discontinuity set to be small. Combined with Theorem 6, this gives the complete picture:
- The Dirichlet function on is discontinuous everywhere (at every point, you can find both rationals and irrationals nearby). The discontinuity set is all of , which has measure , not . Lebesgue’s criterion says: not Riemann-integrable. Topic 25’s opening puzzle is now closed at the most precise possible level.
- is Lebesgue-integrable, with integral (Example 2). The Lebesgue integral handles it gracefully because it doesn’t care about the discontinuity set as long as the function agrees almost everywhere with a “nice” function (the constant zero, in this case).
- A function with finitely many jump discontinuities — a step function, say — has discontinuity set of measure zero, so it is Riemann-integrable. Both integrals agree.
Lebesgue’s criterion is the bridge between the analytic notion of “Riemann-integrable” and the measure-theoretic notion of “almost-everywhere continuous.” It is one of the cleanest results in real analysis: a deep characterization with a one-line statement.
9. Fubini-Tonelli Theorem
The fourth and final big theorem. Up to this point we have integrated functions of one variable on a single measure space. To integrate functions of two (or more) variables, we need a way to combine measures on different spaces into a product measure on the Cartesian product, and a theorem that lets us compute the resulting integral as an iterated integral (one variable at a time).
This completes the preview from Topic 25, Section 9, where we defined the product sigma-algebra but stopped short of building the integral on it.
The construction of the product measure goes as follows: on rectangles with and , set . Carathéodory’s extension theorem (Topic 25, Theorem 2 in spirit) extends this set function to a -additive measure on the product sigma-algebra , provided that both and are -finite — meaning each space can be written as a countable union of measurable sets of finite measure. (Lebesgue measure on is -finite — write .) The -finiteness hypothesis is essential; without it, the product measure construction can fail to be unique.
With in hand, we have an integral defined by the same machinery as before. The Fubini-Tonelli theorems tell us that this integral can be computed as an iterated integral.
🔷 Theorem 8 (Tonelli's Theorem)
Let and be -finite measure spaces, and let be measurable with respect to the product sigma-algebra . Then the maps are measurable on and respectively, and
Tonelli is the “non-negative” half of Fubini-Tonelli. Because , all three integrals are non-negative (possibly ), and the equalities hold without any extra integrability assumption — that is the whole point of Tonelli. For sign-changing functions, we need an additional integrability hypothesis to avoid ambiguities.
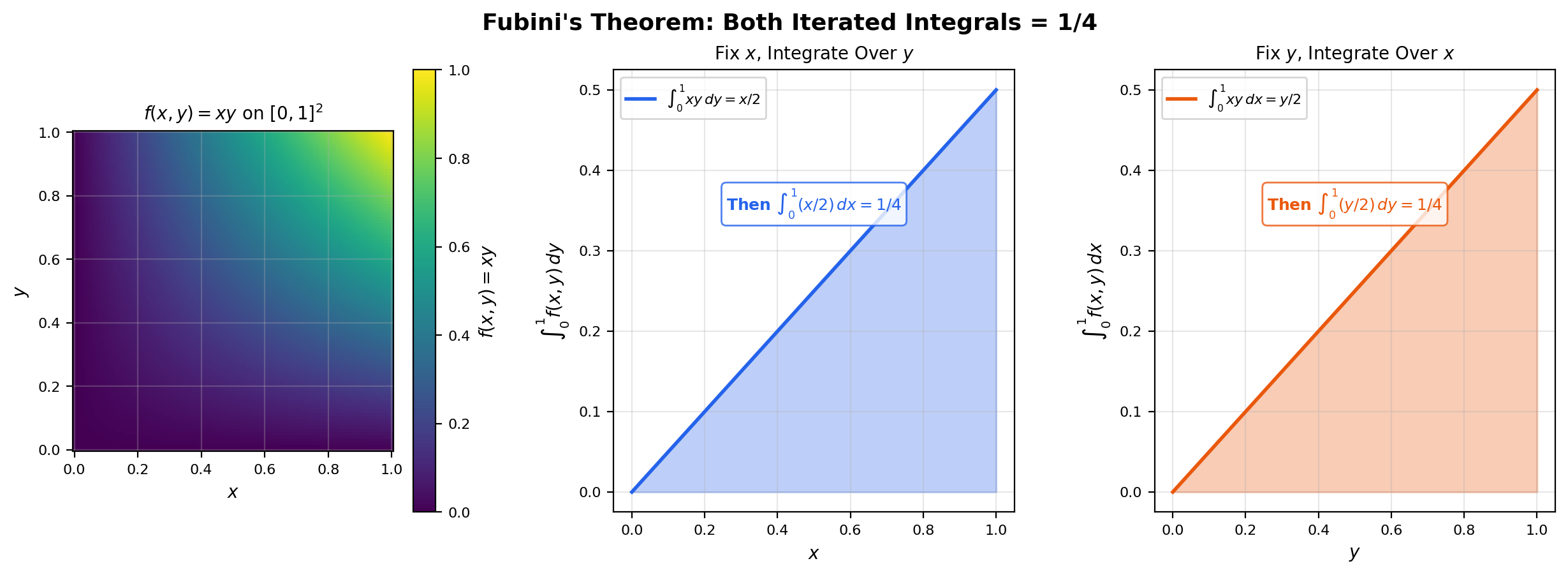
🔷 Theorem 9 (Fubini's Theorem)
Let and be -finite measure spaces, and let be measurable with respect to . If ( is integrable with respect to the product measure), then , the iterated integrals exist for -a.e. (and -a.e. ), and
Proof.
Both theorems are proved by the same four-step “extension by linearity and limits” pattern that runs through all of measure theory.
Step 1: Verify on indicator functions of measurable rectangles. For with , , the iterated integral computation reduces to The other iterated order gives the same answer by symmetry, and the product integral is by definition. All three agree.
Step 2: Extend to indicators of measurable sets. A general measurable set is built up from rectangles via countable unions, intersections, and complements. The “monotone class theorem” (or equivalently the - theorem) lets us promote the rectangle case to the general measurable set case. Briefly: the collection of for which the equality holds is closed under increasing unions and complements, and it contains the rectangles, so it contains the entire generated sigma-algebra.
Step 3: Extend to non-negative simple functions, then to non-negative measurable functions. Linearity of the integral promotes Step 2 from indicators to finite linear combinations of indicators (i.e., simple functions). MCT promotes from non-negative simple functions to non-negative measurable functions: choose an increasing sequence of simple functions , apply Step 3 to each , and pass to the limit using MCT on both the inner integral and the outer integral. This gives Tonelli.
Step 4: Extend to general integrable functions. For , write . Both and both have finite integrals (since ). Apply Tonelli to each separately and subtract. The integrability hypothesis is what guarantees that the subtraction is unambiguous (no ). This gives Fubini.
The full details for Steps 2 and 3 occupy several pages and use a careful application of the - theorem; see Folland §2.5 for the textbook treatment.
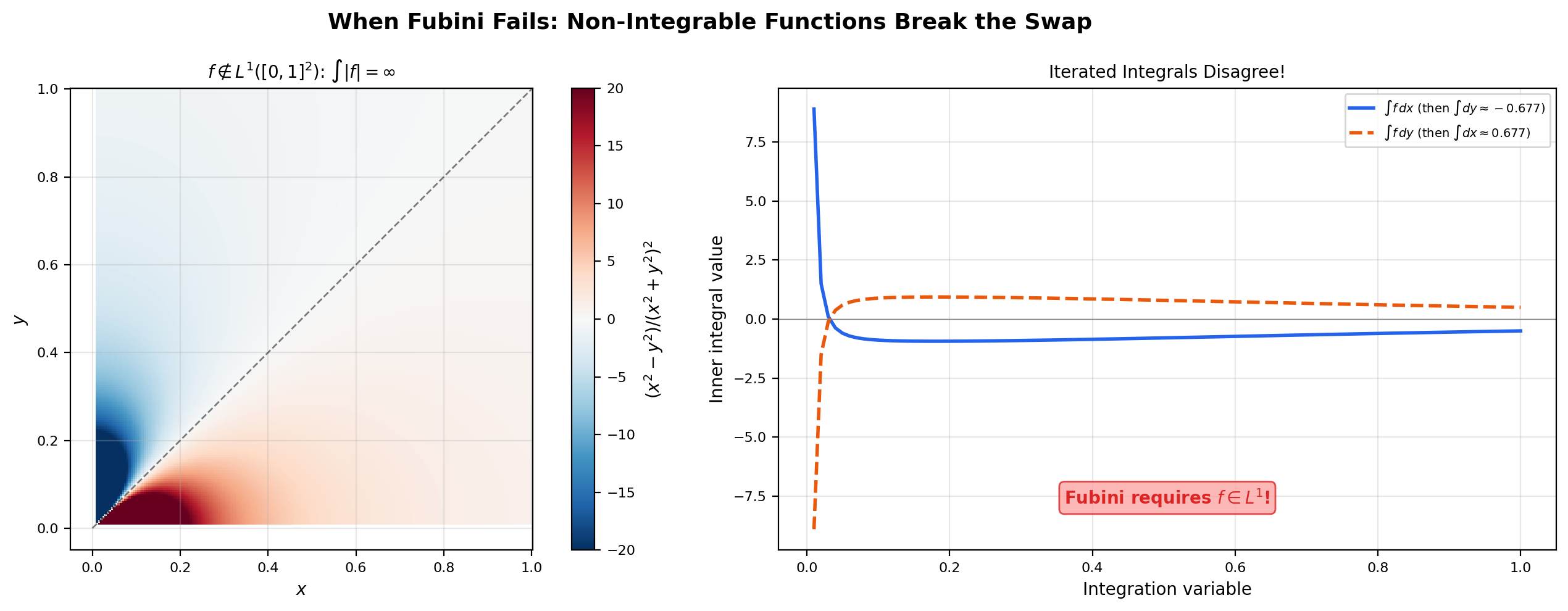
The integrability hypothesis in Fubini is essential. Without it, the iterated integrals can disagree even when both exist as improper limits.
📝 Example 11 (Iterated integrals can disagree without absolute integrability)
Let on (extend by at the origin). A direct computation (or a clever trick: ) gives
The two iterated integrals exist (as improper Riemann integrals) and disagree. Fubini tells us that this can only happen when the integrability hypothesis fails, and indeed — the singularity at the origin is bad enough that the function is not absolutely integrable on . The product integral does not exist.
📝 Example 12 ($E[XY] = E[X] \cdot E[Y]$ for independent random variables via Fubini)
Let be independent real-valued random variables on a probability space . Independence means the joint distribution of on is the product measure (this is the formal definition of independence — see Topic 25, Remark 10). Suppose .
The expected value . By Fubini (the integrability hypothesis follows from and Tonelli applied to , which gives ),
This is the textbook identity “expectation factors over independent variables.” The proof is one application of Fubini. The same argument extends to any finite collection of independent random variables and is the foundation of every “weak law of large numbers” computation.
💡 Remark 8 (Fubini connects back to Topic 13)
The measure-theoretic Fubini theorem (Theorem 9) is the generalization of the Riemann-integral Fubini theorem from Multiple Integrals & Fubini’s Theorem. Same statement — “swap the order of iterated integration” — but now valid on arbitrary -finite measure spaces, not just with Lebesgue measure. In particular, Tonelli’s theorem applied to non-negative integrands on recovers the Topic 13 statement that the order of integration is irrelevant for non-negative continuous functions on a rectangle, and Fubini extends the result to the much broader class of functions on arbitrary product measure spaces (e.g., probability times probability, counting times Lebesgue, -finite times -finite). The Topic 13 version was already enough for almost all calculus computations; the Topic 26 version is what probability theory and functional analysis need.
The interactive viz below lets you choose a function on and see all three integrals — both iterated orderings and the product integral — computed simultaneously. For the smooth and separable cases, all three agree. For the pathological case from Example 11, the iterated integrals disagree visibly.
f(x, y) = xy on [0, 1]². Smooth and integrable. All three integrals agree at 1/4.
10. Computational Notes
A few practical notes on how the Lebesgue integral surfaces in scientific Python.
Numerical integration as Lebesgue approximation. scipy.integrate.quad computes using adaptive Gauss-Kronrod quadrature. Conceptually, this is a sophisticated version of the simple-function supremum from Definition 2: it samples at strategically chosen points, computes a weighted sum, and refines until the estimated error is below a tolerance. The key practical difference from the theoretical definition is that the computer uses finitely many function evaluations (typically 21–63 in a single call), while the Lebesgue supremum is over all simple functions . For smooth integrands the convergence is fast enough that the difference is invisible; for integrands with singularities or oscillations, you can hit the tolerance limit and need adaptive subdivision (scipy.integrate.quad does this automatically) or specialized methods.
Monte Carlo integration. For high-dimensional integrals — say with — quadrature methods scale exponentially in and become unusable. The alternative is Monte Carlo: sample independently from and estimate The strong law of large numbers (which is itself a corollary of MCT and the first Borel-Cantelli lemma from Topic 25) guarantees almost-sure convergence as . The standard error scales as , where — the dimension does not appear. This is the reason every modern probabilistic ML algorithm (variational inference, MCMC, importance sampling, score matching) is built on Monte Carlo rather than quadrature.
torch.distributions and expected values. Every call to dist.mean, dist.variance, or dist.entropy() is computing a Lebesgue integral against the distribution dist. The .log_prob(x) method returns — the log of the Radon-Nikodym derivative of the distribution with respect to Lebesgue measure (when one exists). For discrete distributions, the same method returns — the log probability of the singleton set. The same code path handles both cases because torch.distributions is built on top of a measure-theoretic abstraction in which the underlying reference measure (Lebesgue or counting) is implicit. Topic 28 (Radon-Nikodym) will make this connection precise.
The numerical pitfall: verifying the DCT hypothesis. In practice, finding an integrable dominator is the hardest part of applying DCT correctly. For a parametric family , a common strategy is to dominate by the envelope over a compact parameter set , and verify integrability of the envelope numerically. When you can’t find a dominator, you usually have to fall back on a weaker convergence theorem (Vitali convergence, dominated convergence in measure) or do the computation a different way. If your training loop is silently producing biased gradient estimates, it is likely because you implicitly invoked DCT in a place where the dominator does not exist — exactly the failure mode of the spike sequence in Example 1.
📝 Example 13 (Monte Carlo estimation of $E[\sin(X)]$ for $X \sim \mathrm{Exp}(1)$)
Let be an exponential random variable with rate , so has density on . We want .
A direct integration (integration by parts twice, or recognizing the Laplace transform of ) gives
Monte Carlo: draw i.i.d. from and form . By the strong law of large numbers, almost surely. The standard error is where . A short numerical experiment with typically gives within of .
import numpy as np
N = 10**6
X = np.random.exponential(1.0, size=N)
estimate = np.mean(np.sin(X))
print(estimate) # ≈ 0.5The convergence rate is independent of dimension, which is why the same script generalizes — without modification — to estimating for or .
11. Connections to Statistics
Measure-theoretic probability and the Lebesgue integral are inseparable: is the foundational identity, and the convergence theorems are the mathematical justification for almost every asymptotic argument in statistics.
Expectation as a Lebesgue integral
is a Lebesgue integral of the random variable with respect to the probability measure. Linearity, monotonicity, and the convergence theorems built in this topic are exactly the tools used to prove every expectation identity in statistics. See formalStatistics Expectation & Moments.
Modes of convergence
Dominated Convergence, Monotone Convergence, and Fatou’s lemma form the trinity that justifies interchanging limit and expectation. They appear in every convergence-of-estimator proof: “by DCT, .” This single move is what licenses essentially every asymptotic result in statistics. See formalStatistics Modes of Convergence.
The Strong Law of Large Numbers
The strong LLN almost surely is a statement about the Lebesgue integral : the time-average along a single sample path equals the ensemble average. The proof (Etemadi, Kolmogorov) uses Lebesgue-integral tools throughout — without Lebesgue’s framework, even stating the SLLN rigorously is awkward. See formalStatistics Law of Large Numbers.
Maximum likelihood asymptotics
Consistency and asymptotic normality proofs for the MLE invoke DCT to interchange differentiation and integration (Fisher-information identities) and to pass limits through the log-likelihood. The technical apparatus of measure theory is what underwrites the textbook formula . See formalStatistics Maximum Likelihood.
12. Connections to ML
Four big connections, each substantial enough to be its own research thread.
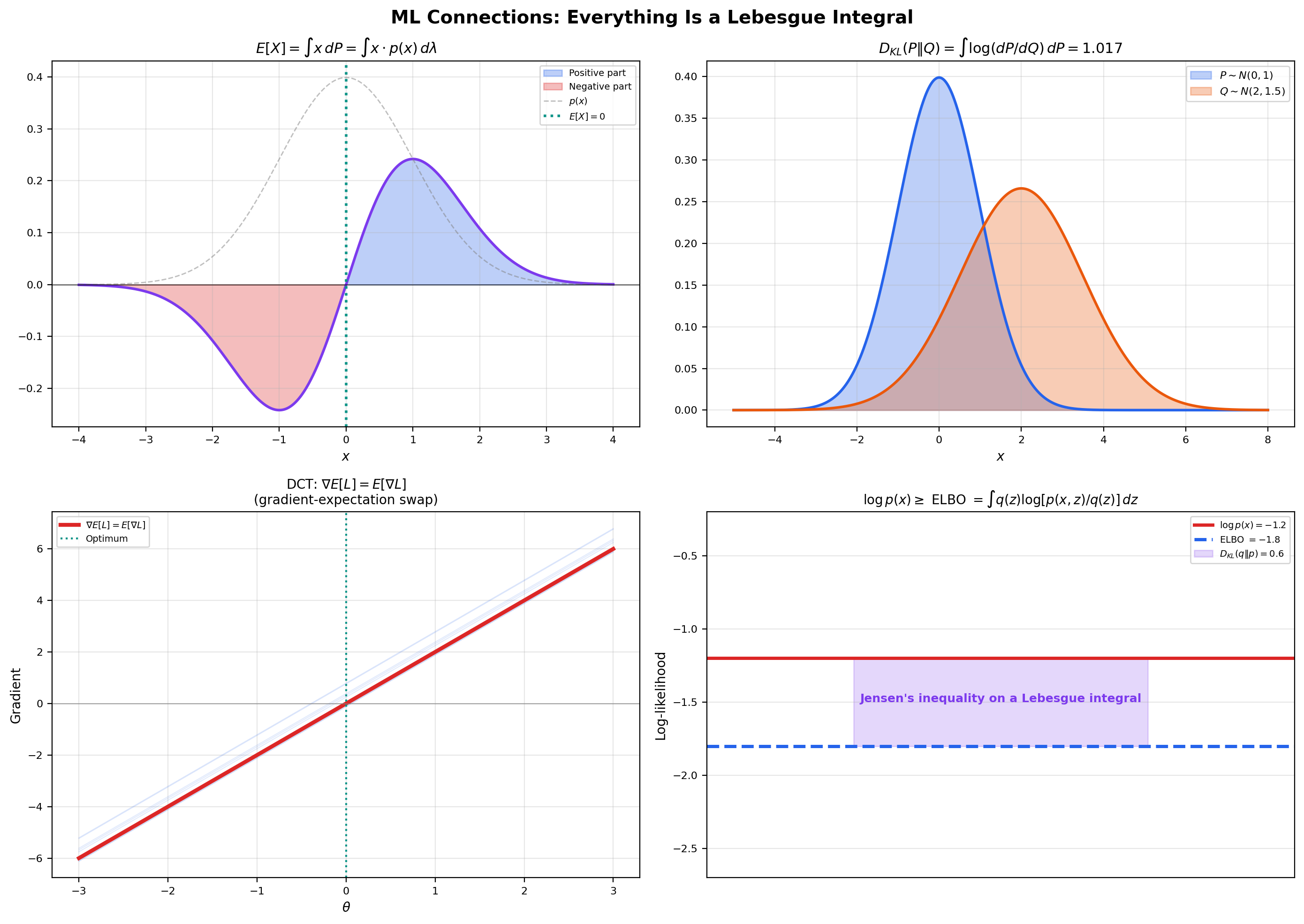
Expected value as a Lebesgue integral. The expected value of a real random variable on a probability space is, by definition, the Lebesgue integral
This single definition unifies all the textbook formulas you have seen in elementary probability. For a discrete random variable taking values with probabilities , the integral against becomes the sum . For a continuous random variable with density with respect to Lebesgue measure, the integral becomes . For the mixture cases that appeared in Puzzle 2 of Section 1, the integral handles the discrete and continuous components in a single uniform formula. Every higher moment (), every moment generating function (), and every characteristic function () is a Lebesgue integral against . The Lebesgue integral is what makes “expectation” a single mathematical operation rather than a family of formulas. Forward link: Probability Spaces.
KL divergence and cross-entropy as Lebesgue integrals. The Kullback-Leibler divergence between two probability measures on a common measurable space, with (meaning is absolutely continuous with respect to ), is
The integrand is the log of a Radon-Nikodym derivative — a measurable function on the underlying space. The integral is taken with respect to . KL divergence is non-negative (a consequence of Jensen’s inequality applied to the convex function , which is itself a Lebesgue integral inequality), zero iff a.e., and convex in both arguments. None of these properties is provable without the Lebesgue framework; they all use integral inequalities that require absolute integrability and the linearity from Theorem 2.
The cross-entropy — the loss function for classification when is the model’s predictive distribution and is the empirical distribution of the training labels — is the same kind of object: a Lebesgue integral of a log-density against a probability measure. Forward link: Information Geometry.
SGD as Dominated Convergence. This is the connection from Puzzle 3 of Section 1 and Example 10 of Section 7. The identity is the mathematical move that makes minibatch gradient descent an unbiased estimator of full-batch gradient descent. The interchange is justified by the Dominated Convergence Theorem applied to the difference quotients in , with the dominator coming from any uniform Lipschitz bound on . In practice, gradient clipping and bounded-support data assumptions are the operational ways to ensure a dominator exists. Every SGD convergence proof in the optimization literature (Robbins-Monro, Nesterov, Adam, anything in the deep learning theory canon) implicitly invokes DCT at this step. Forward link: Gradient Descent.
The ELBO and Jensen’s inequality on integrals. In variational inference, we want to compute the marginal likelihood , which is intractable for most interesting models. The trick is to introduce a tractable variational distribution and use Jensen’s inequality:
The last step is Jensen’s inequality on the concave function , applied to the random variable under the law . The right-hand side is the evidence lower bound (ELBO):
Jensen’s inequality is a Lebesgue integral inequality — it requires being concave plus integrability of both sides, both of which are statements about the integral defined in this topic. The tightness of the ELBO (the gap ) is exactly the KL divergence , which is itself a Lebesgue integral. The whole machinery of variational inference is integral inequalities all the way down. Forward link: Variational Inference.
📝 Example 14 (KL divergence between two Gaussians as a closed-form Lebesgue integral)
Let and be two univariate Gaussians on . Both are absolutely continuous with respect to Lebesgue measure, with densities . The Radon-Nikodym derivative at is , so
Plugging in the Gaussian densities and evaluating the integral (which is a finite computation involving and ), the answer is
This closed form is used inside the reparametrization-trick KL term of the variational autoencoder loss — every VAE that assumes Gaussian posterior and Gaussian prior ships this expression in its loss function.
📝 Example 15 (Verifying the DCT hypothesis for $L^2$-regularized SGD)
Suppose the per-sample loss is for some baseline loss and regularization strength . The gradient is .
Suppose is uniformly bounded: for all in a compact set and -a.e. . (This is the standard “bounded gradient” assumption that holds for any logistic-regression-style model with bounded features.) Then for ,
The constant is finite. The constant function is integrable with respect to any probability measure on (its integral is just ). So the DCT hypothesis is satisfied with dominator , and the interchange is justified for . The minibatch gradient is therefore an unbiased estimator of the population gradient — this is the precise statement that makes SGD work, and the verification took three lines once we knew the dominator structure to look for.
13. Closing Reflection — From Framework to Integral
This is the second topic in Track 7 — Measure & Integration — and the second advanced topic in formalCalculus. Topic 25 built the framework; this topic built the integral. The combination is what makes measure theory a usable tool, not just a piece of mathematical infrastructure: every theorem in this topic is the rigorous version of an everyday calculation in probability theory or machine learning. The next two topics in the track will build the function spaces () and the change-of-measure machinery (Radon-Nikodym) that complete the foundation for modern probability.
If the convergence-theorem proofs felt harder than the proofs in Topic 25, that is accurate, and it is the natural difficulty step-up of moving from “set-theoretic reasoning about measures” to “limit-of-integrals manipulations.” The MCT proof technique (the scaled cutoff , the increasing exhaustion , the diagonal sup over simple functions) is the prototype for almost every proof in measure-theoretic real analysis from this point forward.
- Billingsley, P. Probability and Measure (3rd ed., 1995), Chapters 3–4. The probability-flavored treatment, closest to our ML-connection sections.
Connections & Further Reading
Prerequisites — topics you need first
Sigma-Algebras & Measures
The Lebesgue integral is constructed on the measure-theoretic framework from Topic 25: sigma-algebras, measures, measurable functions, and simple functions are all prerequisites.
The Riemann Integral & FTC
Every Riemann-integrable function is Lebesgue-integrable with the same integral value. The Lebesgue integral strictly extends the Riemann integral to a larger class of functions.
Multiple Integrals & Fubini's Theorem
Fubini's theorem provides the measure-theoretic foundation for the iterated integration techniques from Topic 13. The Fubini-Tonelli theorem generalizes Fubini's theorem for Riemann integrals to arbitrary product measure spaces.
Probability & The Union Bound
Where this leads — next in formalCalculus
Lp Spaces
Banach spaces of measurable functions where ‖f‖_p = (∫|f|^p dμ)^(1/p) < ∞. The completeness theorem (Riesz-Fischer) is a direct application of the Dominated Convergence Theorem from Section 7 — the Lᵖ norm is exactly the right tool to make the convergence-theorem machinery into a complete metric space structure on functions.
Radon-Nikodym & Probability Densities
Characterizes when one measure ν has a density f = dν/dμ with respect to another measure μ. The bridge to probability densities, conditional expectation, and Bayesian inference. The KL-divergence and importance-sampling formulas from Section 11 are special cases formalized there.
On to formalStatistics — where this calculus powers inference
Expectation Moments
E[X] = ∫ X dP is a Lebesgue integral of the random variable w.r.t. the probability measure. Linearity, monotonicity, and the convergence theorems (MCT, DCT, Fatou) are exactly the tools used to prove every expectation identity in the course.
Modes Of Convergence
Dominated Convergence, Monotone Convergence, and Fatou's lemma are the trinity that justify interchanging limit and expectation. They appear in every convergence-of-estimator proof: 'by DCT, lim E[X_n] = E[lim X_n] = E[X].'
Law Of Large Numbers
The strong LLN X̄_n → μ a.s. is a statement about the Lebesgue integral ∫X dP: the time-average along a single sample path equals the ensemble average. The proof (Etemadi, Kolmogorov) uses Lebesgue-integral tools throughout.
Maximum Likelihood
Consistency and asymptotic normality proofs for the MLE invoke DCT to interchange differentiation and integration (Fisher-information identities) and to pass limits through the log-likelihood.
On to formalML — where this calculus powers ML
Gradient Descent
The interchange $\nabla\mathbb{E}[L(\theta, X)] = \mathbb{E}[\nabla L(\theta, X)]$ in SGD convergence proofs is a dominated-convergence-theorem application — the single most important ML use of this topic.
Information Geometry
KL divergence $D_\mathrm{KL}(P \| Q) = \int \log(dP/dQ)\,dP$ and cross-entropy are Lebesgue integrals against probability measures. Their properties (non-negativity, convexity) follow from integral inequalities developed in this topic.
Variational Inference
The ELBO is an integral identity derived from Jensen's inequality applied to a Lebesgue integral: $\log p(x) \ge \int q(z) \log[p(x, z)/q(z)]\,dz$. The continuous-$\theta$ case is structurally identical with sums replacing integrals.
Double Descent
The Marchenko–Pastur measure introduced in §5 is a probability measure on $\mathbb{R}_{\ge 0}$, and §5.2's Stieltjes-transform derivation integrates $1/(\lambda - z)$ against the MP density. Comfort with Lebesgue integration on the line (and limiting arguments through the Stieltjes inversion formula) is the substrate for the §6 closed-form bias-variance integrals.
Gaussian Processes
§2.4's Karhunen–Loève expansion expresses a centered GP as an $L^2$-convergent series of independent Gaussians; §5.1's marginal-likelihood derivation invokes Gaussian–Gaussian convolution, a Lebesgue-integral identity at base.
Generalization Bounds
The risk functional $R(h) = \int \ell(h(x), y)\,dP(x, y)$ is a Lebesgue integral against the population probability measure. The gap between empirical averages (Riemann-style sample sums) and population integrals (Lebesgue integrals) is the central object of every bound here; change-of-variables and dominated-convergence underwrite the convergence claims.
PAC Bayes Bounds
The Radon–Nikodym derivative $dQ/dP$ — central to the change-of-measure inequality in §3 — requires the Lebesgue integral to define and the change-of-variables formula to manipulate. Every $\mathbb{E}_Q[\cdot] = \int \cdot\,dQ$ in the proofs is a Lebesgue integral against the posterior measure.
Variational Bayes For Model Selection
§2's ELBO-as-evidence-bound derivation applies Jensen's inequality to a Lebesgue integral; §10's bits-back coding expected code length is also a Lebesgue expectation. The integral identity is what makes the bound work for continuous-$\theta$ models.
References
- book Royden, H. L. & Fitzpatrick, P. M. (2010). Real Analysis Fourth edition. Chapters 4 (Lebesgue integration on ℝ) and 18 (general measure spaces). Closest to our exposition order.
- book Folland, G. B. (1999). Real Analysis: Modern Techniques and Their Applications Second edition. Chapter 2 (integration), Chapter 3 (signed measures). Concise and rigorous; the source for our Tonelli/Fubini proof sketch.
- book Tao, T. (2011). An Introduction to Measure Theory Free PDF. Chapters 1.4–1.6 (the integral on ℝ, then abstract). Pedagogically closest to our geometric-first approach.
- book Billingsley, P. (1995). Probability and Measure Third edition. Chapters 3–4 (integration, expected values). Probability-flavored treatment closest to our ML connections.